 | Chapter 8 |  |

| Chapter 8 | |
No ties bind so strongly as the links of inheritance.
- Stephen Jay Gould
This chapter is essentially a motley collection of ideas, techniques, and opinions related to Perl objects. I have not attempted to weave these threads too closely. The topics are as follows:
Search for an alternative way of representing object attributes, instead of hash tables. The two strategies examined in this chapter occupy less space and are faster.
How to use AUTOLOAD to automatically forward method calls.
What I find objectionable about inheritance, along with alternative ways of structuring classes.
Hash tables have traditionally been used for storing object attributes. There are good reasons for doing this:
Each attribute is self-describing (that is, the name and type of each attribute are easily obtained from the object), which makes it easy to write readable code. It also helps modules that do automatic object persistence or visualization of objects, without the object's explicit cooperation.
Each class in an inheritance hierarchy can add attributes freely and independently.
In fact, each instance (not just the class) can possess a unique set of attributes and can change this set at run time. The artificial intelligence community often uses this slot- or frame-based approach because it adapts itself very well to new pieces of information.
Of course, not every problem requires this degree of generality. In addition, while Perl's hash tables are fast (within 15% of the speed of arrays) and reasonably compact (key strings are not duplicated), they are not exactly inexpensive. Creating 100 objects means that you have 100 hash tables, each of which tends to optimistically allocate extra space to accommodate future insertions.
This section illustrates two alternate approaches, one using arrays and another using typeglobs. Both approaches are less general than the hash table approach but are faster and leaner. The first is a module called ObjectTemplate developed for this book.[1] The other uses typeglobs and has seen limited application in some standard CPAN modules, most notably IO and Net. I hesitate to suggest this as an alternative approach because it is way too "hackish," but I present it here to enable you to understand these standard modules.
[1] I originally posted a trial version of this approach to comp.lang.perl.misc as a module called ClassTemplate. The version presented here is a significant improvement.
The module presented in this section uses arrays to store attributes (but not the array per object approach). Let us briefly see its usage before moving on to the implementation.
To implement the Employee class, with the attributes "name," "age," and "position," you simply inherit from ObjectTemplate, and supply a list of attribute names to a static method called attributes (exported by ObjectTemplate), as follows:
package Employee; use ObjectTemplate; # Import ObjectTemplate @ISA = qw(ObjectTemplate); # Inherit from it. attributes qw(name age position); # Declare your attributes
That's all. A user of this module can now create Employee objects using a dynamically generated method called new and retrieve and modify attributes using accessor methods (also created automagically):
use Employee;
$obj = Employee->new(
"name" => "Norma Jean",
"age" => 25
); # new() created by ObjectTemplate
$obj->position("Actress");
print $obj->name, ":", $obj->age, "\n";Note that Perl permits you to omit the trailing parentheses for any method call in which there is no ambiguity about its usage. Any word following an arrow is automatically treated as a method, as in the preceding case.
ObjectTemplate provides the following features for an inherited class:
An allocator function called new. This allocates an object blessed into the inherited class. new calls initialize, which in turn can be overridden in the inherited class, as explained earlier.
Accessor methods with the same name as the attributes. These methods are created in the inherited module, and everyone, including the object's own methods, gains access to the attributes only through these methods. This is because ObjectTemplate is the only module that knows how the attributes are stored. For example,
package Employee;
sub promote {
my $emp = shift; # $emp is the object
my $current_position = $emp->position(); # Get attribute
my $next_position = lookup_next_position($current_position);
$r_employee->position($next_position); # Set attribute
}The user package can create its own custom accessor methods with the same naming convention as above; in this case, ObjectTemplate does not generate one automatically. If a custom accessor method wants access to the attribute managed by ObjectTemplate, it can use the get_attribute and set_attribute methods.
new() takes an initializer list, a sequence of attribute name-value pairs.
ObjectTemplate takes attribute inheritance (@ISA) into account, for both the memory layout, and the accessors. Consider
package Employee; use ObjectTemplate; @ISA = qw(ObjectTemplate); attributes qw(name age); package HourlyEmployee; @ISA = qw(Employee); attributes qw(hourly_wage);
In this example, an object of the HourlyEmployee class contains two inherited attributes, name and age, that all employees possess, and hourly_wage, that only hourly employees possess.
All attributes are scalar-valued, so a multivalued attribute such as friends has to be stored as a reference:
attributes qw(friends); $obj->friends([J'Joe']); # an array reference to the accessor
This is of course true of the hash table representation also.
Figure 8.1 shows how ObjectTemplate organizes object attributes.
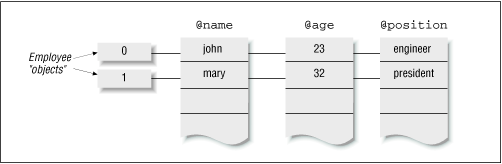
The data structure is quite simple. Instead of allocating one array or hash per object, ObjectTemplate creates only as many arrays as there are attributes (the columns shown in the figure). Each object is merely a "horizontal slice" across these attribute columns. When new() is called, it allocates a new logical row and inserts each element of the initializer array in the corresponding attribute column at the new row offset. The "object," therefore, is merely a blessed scalar containing that row index. This scheme is more space-efficient than the hash approach, because it creates so few container arrays (only as many as there are attributes), and it is faster because array accesses are always a little faster than hash accesses.
There's a slight hitch when an object is deleted. Although the corresponding row is logically free, we can't really move up the rest of the rows below, because the other object references (which are indices) and their data will get out of sync. ObjectTemplate therefore reuses deallocated (free) rows by maintaining a per-package "free list" called @_free. This is a linked list of all free rows with a scalar $_free pointing to the head of this list. Each element of this list contains the row index of the next free row. When an object is deleted, $_free points to that row, and the corresponding index in the free list points to the previous entry pointed to by $_free.
Since the freed and active rows do not overlap, we take the liberty of using one of the attribute columns (the first one) to hold @_free. This is done using typeglob aliasing. Figure 8.2 shows a snapshot of this structure.
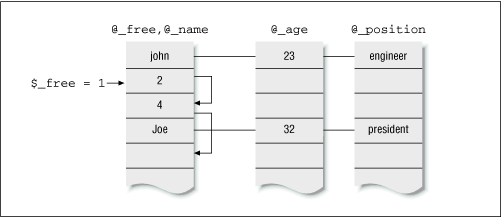
You might have noticed that I'm using the same identifier name, _free, for two variables, $_free and @free. Although I frown on this idea in general, I have used it here for two reasons. First, both are required for the same task; second, one typeglob alias gives us access to both variables in one shot. This is important for performance, as we shall see soon.
ObjectTemplate uses objects, typeglob aliasing, symbolic references, and eval liberally, so if you understand the code below, you can consider yourself a Perl hacker! One way to pore through this code is to read the descriptions supplied in this section while using the debugger to step through a small example that uses this module. Of course, you don't have to understand the code to use it.
package ObjectTemplate;
require Exporter;
@ObjectTemplate::ISA = qw(Exporter);
@ObjectTemplate::EXPORT = qw(attributes);
my $debugging = 0; # assign 1 to it to see code generated on the fly
# Create accessor methods, and new()
sub attributes {
my ($pkg) = caller;
@{"${pkg}::_ATTRIBUTES_"} = @_;
my $code = "";
foreach my $attr (get_attribute_names($pkg)) {
# If a field name is "color", create a global array in the
# calling package called @color
@{"${pkg}::_$attr"} = ();
# Define accessor only if it is not already present
unless ($pkg->can("$attr")) {
$code .= _define_accessor ($pkg, $attr);
}
}
$code .= _define_constructor($pkg);
eval $code;
if ($@) {
die "ERROR defining constructor and attributes for '$pkg':"
. "\n\t$@\n"
. "-----------------------------------------------------"
. $code;
}
}attributes uses symbolic references to create a global array called @_ATTRIBUTES that remembers the attribute names. This array is then used by get_attribute_names to access all attributes defined in the current package and all its super classes. For each such attribute, attributes creates a global array in the current package, as we saw in Figure 8.1. If an accessor has not been defined for that attribute, it calls _define_accessor to generate the method dynamically. Finally, it calls _define_constructor to create the subroutine new directly into the calling package.
sub _define_accessor {
my ($pkg, $attr) = @_;
# This code creates an accessor method for a given
# attribute name. This method returns the attribute value
# if given no args, and modifies it if given one arg.
# Either way, it returns the latest value of that attribute
# qq makes this block behave like a double-quoted string
my $code = qq{
package $pkg;
sub $attr { # Accessor ...
\@_ > 1 ? \$_${attr} \[\${\$_[0]}] = \$_[1] # set
: \$_${attr} \[\${\$_[0]}]; # get
}
if (!defined \$_free) {
# Alias the first attribute column to _free
\*_free = \*_$attr;
\$_free = 0;
};
};
$code;
}_define_accessor is called for every field name given to attributes and for every attribute found in the module's superclasses. For an attribute called age in the Employee module, for example, it generates the following code:
package Employee;
sub age { # Accessor
@_ ? $_age[$$_[0]] = $_[1]; # set
: $_age[$$_[0]]; # get
}
if (!defined $_free) {
*_free = *_age; # Alias the first attribute column
#to _free
$_free = 0;
};$_[0] contains the object, and $_[1] contains the attribute value. Therefore $$_[0] contains the row index, and $_age[$$_[0]] contains the value of the age attribute of that object. In addition, _define_accessor aliases _free to _age if the aliases don't already exist.
sub _define_constructor {
my $pkg = shift;
my $code = qq{
package $pkg;
sub new {
my \$class = shift;
my \$inst_id;
if (defined(\$_free[\$_free])) {
\$inst_id = \$_free;
\$_free = \$_free[\$_free];
undef \$_free[\$inst_id];
} else {
\$inst_id = \$_free++;
}
my \$obj = bless \\\$inst_id, \$class;
\$obj->set_attributes(\@_) if \@_;
\$obj->initialize;
\$obj;
}
};
$code;
}_define_constructor generates code for a constructor called new to be installed in the calling package. new checks the free list, and if it contains rows to spare, it uses the row number from the top of that list. It then undef's the head of the list, because the free list is aliased to the first attribute column, and we don't want that attribute's assessor picking up garbage values. If the free list does not contain any spare rows, the object is assigned the next logical index.
sub get_attribute_names {
my $pkg = shift;
$pkg = ref($pkg) if ref($pkg);
my @result = @{"${pkg}::_ATTRIBUTES_"};
if (defined (@{"${pkg}::ISA"})) {
foreach my $base_pkg (@{"${pkg}::ISA"}) {
push (@result, get_attribute_names($base_pkg));
}
}
@result;
}get_attribute_names recurses through the package's @ISA array to fetch all attribute names. This can be used by anyone requiring object meta-data (such as object persistence modules).
# $obj->set_attributes (name => 'John', age => 23);
# Or, $obj->set_attributes (['age'], [# sub set_attributes {
my $obj = shift;
my $attr_name;
if (ref($_[0])) {
my ($attr_name_list, $attr_value_list) = @_;
my $i = 0;
foreach $attr_name (@$attr_name_list) {
$obj->$attr_name($attr_value_list->[$i++]);
}
} else {
my ($attr_name, $attr_value);
while (@_) {
$attr_name = shift;
$attr_value = shift;
$obj->$attr_name($attr_value);
}
}
}set_attributes is given a list of attribute name-value pairs and simply calls the accessor method for each attribute. It can also be called with two parameters; an array of names and an array of values.
# @attrs = $obj->get_attributes (qw(name age));
sub get_attributes {
my $obj = shift;
my (@retval);
map $obj->${_}(), @_;
}get_attributes uses map to iterate through all attribute names, setting $_ to each name in every iteration. The first part of map simply calls the corresponding accessor method using a symbolic reference. Because of some weird precedence issues, you cannot omit the curly braces in ${_}.
sub set_attribute {
my ($obj, $attr_name, $attr_value) = @_;
my ($pkg) = ref($obj);
${"${pkg}::_$attr_name"}[$$obj] = $attr_value;
}
sub get_attribute {
my ($obj, $attr_name, $attr_value) = @_;
my ($pkg) = ref($obj);
return ${"${pkg}::_$attr_name"}[$$obj];
}The get/set_attribute pair updates a single attribute. Unlike the earlier pair of methods, this pair does not call an accessor; it updates the attribute directly. We saw earlier that attributes does not attempt to create accessor methods for those that already exist. But if the custom accessors still want to use the storage scheme provided by ObjectTemplate, they can use the get/set_attribute pair. The expression ${pkg}::_$attr_name represents the appropriate column attribute, and $$obj represents the logical row. (Recall that the object is simply a reference to an array index.) These methods are clearly not as fast as the generated accessor methods, because they use symbolic references (which involve variable interpolation in a string and an extra hash lookup).
sub DESTROY {
# release id back to free list
my $obj = $_[0];
my $pkg = ref($obj);
local *_free = *{"${pkg}::_free"};
my $inst_id = $$obj;
# Release all the attributes in that row
local(*attributes) = *{"${pkg}::_ATTRIBUTES_"};
foreach my $attr (@attributes) {
undef ${"${pkg}::_$attr"}[$inst_id];
}
$_free[$inst_id] = $_free;
$_free = $inst_id;
}DESTROY releases all attribute values corresponding to that object. This is necessary because the object is merely a reference to an array index, which, when freed, won't touch the reference counts of any of the attributes. A module defining its own DESTROY method must make sure that it always calls ObjectTemplate::DESTROY.
sub initialize { }; # dummy method, if subclass doesn't define one.Modules are expected to override this method if they want to do specific initialization, in addition to what the automatically generated new() does.
There are (at least) two areas that could use considerable improvement. One is that get_attributes and set_attributes are slow because they always call accessor methods, even if they know which accessors are artificially provided. Because set_attributes is called by the automatically generated new, it slows down object construction dramatically. (Using this new without arguments is twice as fast as allocating an anonymous hash, but after invoking set_attributes, it is around three times slower.)
Second, custom accessor methods suffer in speed because they are forced to invoke the other slow pair, get_attribute and set_attribute. Possibly a better alternative is to dynamically generate accessor methods prefixed with an "_", so that the developer can write normal accessor methods (without the prefix), and also call these private methods.
You might also want to check out the MethodMaker module available on CPAN, and the Class::Template module that is bundled with the standard distribution. These modules also create accessor methods automatically but assume that the object representation is a hash table. If you like the interface these modules provide, you can attempt to merge their interface with the attribute storage scheme of ObjectTemplate.
This approach, as we mentioned earlier, is not exactly a paragon of readability and is presented here only because it is used in some freely available libraries on CPAN, like the IO and Net distributions. If you don't wish to understand how these modules work, you can easily skip this section without loss of continuity.
We learned from Chapter 3, Typeglobs and Symbol Tables, that a typeglob contains pointers to different types of values. If we somehow make a typeglob into an object reference, we can treat these value pointers as attributes and access them very quickly. Consider the following foo typeglob:
${*foo} = "Oh, my!!" ; # Use the scalar part to store a string
@{*foo} = (10, 20); # Use the array part to store an array
open (foo, "foo.txt"); # Use it as a filehandleWe are able to hang different types of values (at most one of each type) from just one identifier, foo. If we want many such objects, we can use the Symbol module in the Perl library to create references to dynamically created typeglobs:
use Symbol; $obj = Symbol::gensym(); # ref to typeglob
$obj contains a reference to a typeglob. The different parts of a typeglob can be individually accessed (by replacing foo with $obj):
${*$obj} = "Oh, my!!" ; # Use the scalar part to store a string
@{*$obj} = (10, 20); # Use the array part to store an array
open ($obj, "foo"); # Use it as a filehandleClearly, this is a hideous approach for most general objects; if you need another scalar-valued attribute, for example, you have no option but to put it in the hash part of this typeglob. The reason why the IO group of modules uses this hack is that an instance of any of these modules can be treated as a filehandle and passed directly (without dereferencing) to the built-in I/O functions such as read and write. For example:
$sock = new IO::Socket( ... various parameters ...) ;
print $sock "Hello, are you there";
$message = <$sock>;We'll use IO::Socket module extensively in the chapters on networking with sockets.[2]
[2] You don't have to know the following technique, or how the IO::Socket module is built, to use it.
Let us build a small module called File to examine this technique in greater detail. This module allows you to open a file and read the next line; in addition, it allows you to put back a line so that the next attempt to read the file returns that line:
package main;
$obj = File->open("File.pm");
print $obj->next_line();
$obj->put_back("------------------------\n");
print $obj->next_line(); # Should print the string put back above
print $obj->next_line();Since this code opens the File module itself, it should print the following:
package File; ------------------------ use Symbol;
This module uses the scalar part of the typeglob object as a "putback" buffer, the array part of the typeglob to store all the lines read from the file, and the filehandle part of the typeglob to store the filehandle. The implementation of the File module is shown in Example 8.1.
package File;
use Symbol;
sub open {
my ($pkg, $filename) = @_;
$obj = gensym(); # Allocate a typeglob
open ($obj, $filename) || return undef; # Use it as a filehandle
bless $obj, $pkg; # Upgrade to a File "object"
}
sub put_back {
my ($r_obj, $line) = @_;
${*$r_obj} = $line; # The scalar part holds the
} # current line
sub next_line {
my $r_obj = $_[0];
my $retval;
if (${*$r_obj}) { # Check putback buffer
$retval = ${*$r_obj}; # yep, it's got stuff
${*$r_obj} = ""; # empty it.
} else {
$retval = <$r_obj>; # no. read from file
push(@{*$r_obj}, $retval); # add to history list.
}
$retval;
}
1; |  | |
| 7.6 Resources |  | 8.2 Delegation |